[글또 10기] 논문 소개 - LLM vs XGBoost. 머신러닝은 약육강식이 아닌 적자생존!
들어가기 전에
머신러닝, 자연어처리나 인공지능 등에 관심이 있는 사람이라면 제목부터 뭔가 뜬금없다고 생각할 수 있습니다. 분명 XGBoost는 비교적 단순한 머신러닝 알고리즘 아니었나? 하시는 분들이 많으실 겁니다 ChatGPT 를 필두로 세상을 뒤흔든 LLM과 비교적 단순한 통계학 기반 머신러닝 모델의 비교라니, 이 무슨 블랙 위도우랑 스칼렛 위치가 싸우는 소리인가 궁금하실 겁니다. 허나, AI 의 세계는 그렇게 단순하지는 않습니다. 딥 러닝의 대두에도 불구하고 RF, 로지스틱 회귀, SVM 등의 모델들은 여전히 현역입니다. 딥 러닝 알고리즘 끼리만 비교해봐도 RNN, GAN 등이 나왔지만 아직도 영상인식 분야에서는 CNN을 압도하지 못했습니다 (구조상의 이유가 크지만요).
따라서 블랙 위도우와 스칼렛 위치라고 이해하기 보다는, 드론과 공격헬기로 비유하는 게 더 적절하다 생각합니다. 공격 헬기가 드론에 비교해서 훨씬 비싸고 탑재무장도 많지만 드론이 효율적인 상황이 더 많이 나와서 요즘 전쟁에서 드론이 각광받는 것 처럼, AI 모델의 세계는 단순한 복잡도나 포텐셜 보다는, 가성비가 더 좌우할 때가 많습니다.

논문 소개
소개해드릴 논문은 미국 스탠퍼드 대학교의 Matyas Bohacek 과 영국 University College Loondon (이하 UCL) 의 Michal Bravansky 가 공동 집필한 “When XGBoost Outperforms GPT-4 on Text Classification: A Case Study” 라는 논문입니다. 두 저자들은 GPT-4 와 LLAMA 2 라는 최신 LLM들을 비교적 오래된 텍스트 선별 기법인 XGBosst 와 비교했습니다.
다들 잘 알다시피, LLM은 문장 작성과 더불어서 텍스트 이해 및 추론도 잘합니다. 최근에 저 역시 GPT를 가지고 “내가 <용과 같이> 의 이러이러한 캐릭터들을 좋아하고, 그 중에서 누구누구랑은 닮았다는 소리를 듣는데 왜 그럴 거 같니?” 하면서 ChatGPT 와 수다를 떨어봤는데, <용과 같이> 시리즈를 옛날부터 해온 올드팬인 제가 보기에도 상당히 그럴싸한 이유들을 대는 걸 보면서 저를 깜짝 놀라게 했습니다.
연구 내용
연구진은 체코어로 된 Verifee News trustworthiness Dataset (링크) 을 활용해서 실험했습니다. Verifee News trustworthiness Dataset 은 뉴스를 분석해서 클릭유도, 가짜뉴스, 혐오선동 등을 걸러낼 수 있게 하려는 용도로 만들어진 데이터셋입니다. 문서 작성 스타일, 단어, 그리고 문법 등을 활용해서 (아무래도 소위 말하는 '기레기'는 문법이나 사용하는 언어 등에서 수준이 낮다는 사실이 티가 나지 않을까요?) 뉴스를 C(credible) 에서 M(manipulative) 등급으로 판별합니다. 연구진은 GPT-4와 LLAMA 2의 변별 결과와, Electra(참조) 를 활용해서 전처리 한 뒤에 XGBoost 로 판별한 결과를 비교, 대조했습니다.
두 결과의 Confusion Matrix 는 다음과 같습니다.
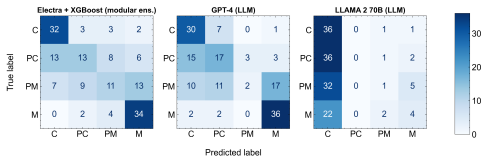
보시다시피 Electra + XGBoost 가 가장 높고 (F1 score 0.533), 그다음이 GPT-4(0.531), 그리고 소형 모델의 한계점때문에 당연하지만 LLAMA 2(0.188) 가 가장 약한 퍼포먼스를 보였습니다. 허나 딥러닝과 머신러닝 파이프라인의 덩치 차이를 생각한다면 LLAMA 2 는 스포츠 용어로 '먹튀' 라고 해도 될 정도의 퍼포먼스입니다. RAM 은 거의 1400 배 넘게 먹는데 F1 score는 거의 1/5 수준이면 아스날의 먹튀 니콜라 페페의 망령이 아른거리는 퍼포먼스네요. 반대로 GPT-4는 이름값과 돈값을 합니다.

결론 - 데이터 엔지니어링과 적절한 모델 선정은 고비용 LLM을 압도할 수 있다?
아마 이 글을 읽으시는 분들 중 대다수는 현업에 종사하시는 분들일 거 같습니다. MLOps 나 LLMOps 등에 관심이 있으시고, 그쪽 관련된 정보를 위해 읽으셨을 듯 합니다. 아무래도 MLOps 의 주 업무가 머신 러닝 시스템을 유지 보수하는 일인 만큼, 배치된 모델의 가성비에 대한 이야기는 와닿으실 수 있다 생각합니다. 닭 잡는 데 소 잡는 칼을 쓰지 않듯, 필요한 업무에 따라서 (예를들면 앞서 말한 가짜뉴스 판별 같은 경우는 기존 classification algorithm 도 충분히 잘 작동하므로) GPT 나 Claude 같은 대형 모델에 의존하기보다는 전처리 후 가벼운 ML 알고리즘을 활용하는것도 경쟁력 있는 방향 같습니다.
허나, 이 연구 역시 맹점이 있습니다. 먼저, GPT나 LLAMA 는 파인튜닝되지 않은 날 것 그대로의 제로샷 / 퓨 샷 모델입니다. XGBoost 알고리즘을 하이퍼파라미터 튜닝해서 고점을 뽑아보고, GPT-4 나 LLAMA-2 를 파인튜닝해서 고점을 뽑아 본 뒤에, 만일 XGBoost는 F1 score 가 0.6 인데 GPT는 0.8대를 뽑는다? 하면 다른 이야기가 될 수 도 있다고 생각합니다.